Etude comparative avec resampling
en vue de détecter un éventuel « stacking effect »
dans la régression sur les données d’Agape
Laetitia Puecha, Frédérick Garciab
et Bernard M. Auriolc
a Université Toulouse I and Université Toulouse III.
c Institut Métapsychique International (IMI), Paris.
| |
La présente étude vise à identifier et quantifier autant que possible l'intervention - ou non - de ce phénomène. Pour cela, nous allons utiliser de fausses cibles, recalculer les "succès" sur ces fausses cibles, sélectionner les essais significatifs, opérer une régression "stepwise" semblable à celle qui a été réalisée sur les données réelles : si les mêmes facteurs se dégagent, c'est qu'ils sont liés au stacking effect, sinon, nous sommes plus probablement en présence d'une phénomène de type ESP.
1. Effet du protocole sur la bonne réponse
Lorsque les émetteurs doivent choisir une image parmi deux, la distribution du pourcentage de bonnes réponses est centrée en ½ (pour deux images), en 1/3 (pour trois mots) et en 1/5 pour (cinq mots) c’est-à-dire sur le pourcentage de bonnes réponses attendu sous l’hypothèse de choix au hasard.
Test d’égalité au hasard
Nous avons testé pour le
protocole à deux images (respectivement trois mots et cinq mots) si le
pourcentage « ![]() » de bonnes réponses était égal à p0=1/2
(respectivement à 1/3 et 1/5), c’est à dire égal à l’espérance du hasard.
» de bonnes réponses était égal à p0=1/2
(respectivement à 1/3 et 1/5), c’est à dire égal à l’espérance du hasard.
Les hypothèses de ce test sont :
H0 : p = p0 contre H1 : p ¹ p0
La statistique
utilisée est :  où n est le nombre
d’essais associés à chaque protocole. Elle suit une loi du khi deux à un degré
de liberté.
où n est le nombre
d’essais associés à chaque protocole. Elle suit une loi du khi deux à un degré
de liberté.
|
|
Nombre d’essais |
Pourcentage de
bonnes réponses |
P-value |
|
2 images |
27060 |
49,96% |
0.884 |
|
3 mots |
104920 |
33,31% |
0.907 |
|
5 mots |
120663 |
20,13 % |
0.257 |
La définition d’un essai relativement meilleur que le hasard n’est donc pas la même selon que l’essai a été réalisé en proposant deux images, trois mots ou cinq mots aux récepteurs pour effectuer leur choix.
On dira qu’un essai est réussi dans le protocole à deux images si le pourcentage de votes pour la cible émise est significativement plus grand que le hasard (1/2). Pour trois mots, le seuil est fixé à 1/3 et pour cinq mots à 1/5. Une autre conséquence de cette remarque est que l’on ne peut pas comparer un succès de 1/3 dans le protocole à deux images (inférieur au hasard) avec un succès de 1/3 dans le protocole à trois mots (égal au hasard) ou avec un succès de 1/3 dans le protocole à cinq mots (supérieur au hasard).
Une possibilité serait donc de travailler à nombre de cibles fixées. Cela n’a pas été possible pour les raisons suivantes.
Dans le cadre du projet Agape, des variations de protocole ont été utilisées pour des raisons pratiques tenant à la nature du matériel disponible et à la configuration des lieux. Quand on a voulu tester si un changement des cibles possibles, à chaque essai, serait favorable, on a dû passer de cinq cibles possibles à trois. En effet, les cinq cibles étant toujours les mêmes au cours de la session, on pouvait les afficher sur un paper-board ; alors que, les cibles variant à chaque essai devaient être affichées sur un moniteur d’ordinateur. Pour obtenir un affichage clair, perceptible depuis le fond de la salle des récepteurs, nous avons dû réduire le nombre de cibles possibles à trois.
Lorsque nous avons voulu appliquer le même type de protocole à des cibles-images (au lieu de mots), nous avons dû, pour les mêmes raisons de visibilité, employer un écran par cible possible. Pour éviter trop de complications hardware et pour réduire le coût, nous avons dû nous limiter à deux cibles (deux écrans).
Par ailleurs, il arrive que certaines variables aient des modalités constantes dans le cadre d’un des trois grands protocoles (2 images, 3 mots, 5 mots) :
- Pour le protocole à deux images : la récompense groupale est toujours donnée en fonction de la majorité relative, la récompense individuelle a toujours été l’affichage du nom des récepteurs, les participants n’ont pas choisi la liste des cibles possibles en début de séance, le temps maximal pour répondre n’a pas varié (il est resté à 60 secondes).
- Pour le protocole à trois mots : les participants n’ont pas choisi la liste des cibles possibles en début de séance.
- Pour le protocole à cinq mots : les émetteurs n’ont jamais eu la consigne de se concentrer sur la cible ou sur les récepteurs, le temps d’écran blanc a été de 0 ou 5 secondes (ce qui est assez court par rapport à l’ensemble des temps d’écran blanc possibles et qui vont jusqu’à 60 secondes).
Afin de pouvoir tester l’effet de chaque modalité des variables, nous avons eu recours à une transformation de la variable d’intérêt « pourcentage de succès » qui permet de rendre comparable des pourcentages de succès obtenus avec deux images, trois ou cinq mots.
où : - ![]() est le pourcentage de bonnes réponses de l’essai ;
est le pourcentage de bonnes réponses de l’essai ;
- p est le pourcentage attendu sous l’hypothèse de choix au hasard
(1/2 pour deux images, 1/3 pour trois mots et 1/5 pour cinq mots).
Si on s’intéresse à la « qualité » des essais, on peut tester si le pourcentage de succès obtenu pour chaque essai est significativement moins bon que le hasard, significativement meilleur que le hasard ou égal au hasard à un seuil de 5% grâce à un test du c2.
La statistique de ce test,
calculée pour chaque essai, est : 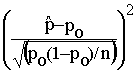 ~ c2 à un degré de
liberté avec les notations définies précédemment.
~ c2 à un degré de
liberté avec les notations définies précédemment.
Dans un premier temps, nous sélectionnons donc les essais significativement différents de l’espérance du hasard (soit 1/2 pour deux cibles, 1/3 pour 3 cibles et 1/5 pour 5 cibles) en réalisant un test du c².
On obtient les résultats suivants (avec un seuil de 5%) :
|
|
Données non permutées |
1ère
permutation |
2ème
permutation |
3ème
permutation |
4ème
permutation |
5ème
permutation |
|
|
Nombre d’essais |
Nombre d’essais |
Nombre d’essais |
Nombre d’essais |
Nombre d’essais |
Nombre d’essais |
|
Supérieurs au hasard |
1079 |
1047 |
1028 |
1052 |
1011 |
1073 |
|
Inférieurs au hasard |
410 |
426 |
423 |
435 |
454 |
460 |
Lors de cette étude, nous tentons d’expliquer le pourcentage de succès.
Si les variables explicatives retenues restent les mêmes après permutation, c’est que leur valeur explicative est indépendante de la cible réelle et ne dépend que des liens de dépendance liant les réponses entre elles (stacking effect).
Les permutations sont réalisées comme suit :
- 1ère permutation : on crée la variable « cible2 » = la variable « cible » décalée d’une ligne
- 2ème permutation : on crée la variable « cible3 » = la variable « cible » décalée de deux lignes
- 3ème permutation : on crée la variable « cible4 » = la variable « cible » décalée de trois lignes
- 4ème permutation : on crée la variable « cible5 » =
- la variable « cible » décalée de quatre lignes (pour 2 mots)
- 1 si « cible »=3, 2 si « cible »=1, 3 si « cible »=2 (pour 3 images)
- 1 si « cible »=5, 2 si « cible »=1, 3 si « cible »=2, 4 si « cible »=3, 5 si « cible »=4 (pour 5 images)
5ème permutation : on crée la variable « cible6 »
- 1 si « cible »=2 et 2 si « cible »=1 (pour 2 mots)
- 1 si « cible »=2, 2 si « cible »=3, 3 si « cible »=1 (pour 3 images)
- 1 si « cible »=3, 2 si « cible »=4, 3 si « cible »=5, 4 si « cible »=1, 5 si « cible »=2 (pour 5 images)
Si on décide de faire une régression en prenant la totalité des essais, on serait amené à expliquer par le protocole un fort pourcentage de bonnes réponses non significativement différentes du hasard, ce qui n’est pas notre propos.
On cherche au contraire à mettre en évidence des caractéristiques qui influencent la « bonne » (identique à ciblei) ou la « mauvaise » réponse (différente de ciblei). On se concentre donc sur les essais significativement inférieurs ou supérieurs au hasard. Ensuite, nous retenons les variables significatives grâce à une procédure pas-à-pas (stepwise) avec un seuil de tolérance de 5%.
Si l’on veut mettre en évidence des facteurs qui influencent la télépathie, il paraît naturel de s’intéresser aux essais significativement supérieurs au hasard. Cependant, on se propose aussi d’étudier les essais significativement inférieurs au hasard car on peut penser qu’ils sont la manifestation d’un phénomène de « psi-missing », c’est-à-dire d’un refus inconscient de donner la bonne réponse malgré la réception du message en provenance des émetteurs.
1.1 Analyse des essais significativement supérieurs au hasard :
On se place ici dans le cas où la variable de bonnes réponses transformée (h) est significativement supérieure au hasard.
On retrouve certaines variables que les données soient permutées ou non. Il s’agit de :
- trois variables qualitatives : choix de la cible, présence de récompense groupale et temps de réponse maximal de 20 secondes ;
- trois variables quantitatives : possibilité de raccourcissement du temps laissé aux récepteurs pour voter dès que la moitié de l’effectif a répondu, rapport {nombre d’émetteurs / effectif total} et rapport {nombre d’émetteurs / nombre de récepteurs} ;
Les estimations sont données dans les tableaux suivants :
|
|
|
Données non permutées |
1ère permutation |
2ème permutation |
3ème permutation |
4ème permutation |
5ème permutation |
5ème permutation |
Variable
|
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
|
|
Constante |
+ 0.92 |
+ 0.91 |
+ 0.82 |
+ 0.78 |
+ 0.78 |
+ 0.93 |
+ 0.93 |
|
|
Variables Qualitatives |
Les émetteurs ont eu une consigne |
+ 0.10 |
+ 0.06 |
|
|
+ 0.10 |
|
|
|
Les participants ont choisi la liste des cibles |
- 0.29 |
- 0.32 |
- 0.30 |
- 0.32 |
- 0.30 |
- 0.32 |
- 0.32 |
|
|
Il y a eu une forme de récompense groupale |
- 0.11 |
- 0.08 |
- 0.09 |
- 0.11 |
- 0.10 |
- 0.06 |
- 0.06 |
|
|
Il y a eu une forme de récompense individuelle |
+ 0.04 |
|
+ 0.06 |
|
|
|
|
|
|
Temps maximum de réponse (20 secondes) |
+ 0.13 |
+ 0.20 |
+ 0.19 |
+ 0.21 |
+ 0.19 |
+ 0.15 |
+ 0.15 |
|
|
Temps maximum de réponse (60 secondes) |
+ 0.19 |
+ 0.21 |
+ 0.24 |
|
|
+ 0.17 |
+ 0.17 |
|
|
Temps maximum de réponse (120 secondes) |
+ 1.08 |
+ 1.04 |
+ 1.05 |
|
|
+ 0.98 |
+ 0.98 |
|
|
Variables Quantitatives |
Possibilité de raccourcissement du temps laissé
aux récepteurs pour voter dès que la moitié de l’effectif ait répondu |
+ 0.07 |
+ 0.13 |
+ 0.07 |
+ 0.12 |
+ 0.09 |
+ 0.13 |
+ 0.13 |
|
Rapport nombre d’émetteurs / effectif total |
- 1.06 |
- 1.31 |
- 0.81 |
- 1.16 |
- 1.50 |
- 1.58 |
- 1.58 |
|
|
Rapport nombre d’émetteurs / nombre de récepteurs |
+ 0.86 |
+ 1.02 |
+ 0.82 |
+ 0.93 |
+ 1.13 |
+ 1.13 |
+ 1.13 |
Au vu de ces tableaux, certaines remarques peuvent être effectuées, que les données aient subi ou non des permutations :
- La constante est positive ce qui signifie que l’on se trouve bien sur l’ensemble des essais significativement meilleurs que le hasard. En effet, si l’on examine la façon dont la variable h est construite, un pourcentage de bonnes réponses supérieur à la valeur attendue sous hypothèse de réponse au hasard correspond à des valeurs positives de h ;
- L’application d’un protocole visant à écourter le temps de réponse des récepteurs a été un facteur favorisant un pourcentage élevé de bonnes réponses ;
- Par contre, si les participants ont eu la possibilité de choisir la liste des cibles potentielles ou que la séance comprenait une forme de récompense groupale, le pourcentage de bonnes réponses par essai a été relativement moins élevé (tout en étant significativement supérieur au pourcentage attendu sous hypothèse de réponse au hasard) ;
- L’interprétation des deux ratios « nombre d’émetteurs / effectif total » et « nombre d’émetteurs / nombre de récepteurs » doit se faire conjointement car ils impliquent les mêmes variables brutes. Pour que l’effet des deux ratios sur la variables aléatoire h se compense, il faut que le nombre de récepteurs soit deux fois plus important que le nombre d’émetteurs.
1.2 Analyse des essais significativement moins bons que le hasard :
On se place ici dans le cas où la variable de bonnes réponses transformée (h) est significativement inférieure au hasard.
On retrouve certaines variables que les données soient permutées ou non. Il s’agit de :
- deux variables qualitatives : choix de la cible, présence de consigne ;
- une variable quantitative : rapport nombre d’émetteurs / nombre de récepteurs ;
Les valeurs des estimations sont données dans les tableaux suivants :
|
|
|
Données non permutées |
1ère
permutation |
2èrm
permutation |
3ème
permutation |
4ème
permutation |
5èmm
permutation |
|
Variable |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
|
|
Constante |
- 1.2080 |
- 1.4265 |
- 1.4323 |
- 1.4237 |
- 1.2366 |
- 1.4527 |
|
|
Variables Qualitatives |
Les émetteurs ont eu une
consigne |
- 0.0948 |
- 0.1217 |
- 0.1537 |
- 0.1493 |
- 0.089 |
- 0.1529 |
|
Les participants ont
choisi la liste des cibles |
+ 0.2222 |
+ 0.2381 |
+ 0.3060 |
+ 0.3137 |
+ 0.262 |
+ 0.3362 |
|
|
Il y a eu une forme de
récompense groupale |
|
+ 0.1209 |
+ 0.0614 |
+ 0.0689 |
|
+ 0.0711 |
|
|
Temps maximum de réponse
(60 secondes) |
|
- 0.1364 |
|
|
|
|
|
|
Il y a eu une forme de
récompense individuelle |
+ 0.0986 |
+ 0.0995 |
|
|
- 0.0433 |
|
|
|
Variables Quantitatives |
Possibilité de
raccourcissement du temps laissé aux récepteurs pour voter dès que la moitié
de l’effectif ait répondu |
- 0.0803 |
|
|
|
+ 1.0146 |
+ 1.1549 |
|
Rapport nombre d’émetteurs
/ effectif total |
|
|
+ 1.3662 |
+ 1.0552 |
- 0.4935 |
- 0.4904 |
|
|
Rapport nombre d’émetteurs
/ nombre de récepteurs |
- 0.1295 |
- 0.1477 |
- 0.6501 |
- 0.485 |
4ème
permutation |
5èmm
permutation |
Les interprétations seront faites dans l’esprit de mettre en évidence les variables qui favorisent la mauvaise réponse, c’est-à-dire qui influent négativement sur la valeur de h. En effet, s’étant placé sur les essais significativement moins bons que le hasard, une variable qui influe positivement sur la valeur de h traduit un rapprochement à la valeur attendue sous hypothèse de réponse au hasard.
L’application d’un protocole visant à écourter le temps de réponse des récepteurs a été un facteur de détérioration du pourcentage de bonnes réponses (cf. données non permutées et 4ème permutation).
S’il y a eu une forme de récompense individuelle, le pourcentage de bonnes réponses s’est rapproché de celui attendu sous hypothèse de réponse au hasard (cf. données brutes et 1ère permutation).
Il paraît intéressant que le protocole visant à raccourcir le temps de réponse améliore la bonne réponse sur les essais significativement supérieurs au hasard et augmente l’échec sur les essais significativement inférieurs au hasard.
On pourrait interpréter ce phénomène grâce à la présence de psi-missing. En effet, on peut penser que sur les essais significativement inférieurs au hasard le message est bien reçu, mais qu’inconsciemment il est mal retranscrit.
Donc, si le pourcentage d’échec augmente sur les essais significativement inférieurs au hasard lorsque l’on utilise un protocole visant à raccourcir le temps de réponse sous l’hypothèse d’existence de psi-missing, cela pourrait traduire que le message est reçu par de plus de personnes tout en étant mal retranscrit.
Nous pouvons souligner que la présence de récompense groupale et le ratio « nombre d’émetteurs / effectif total » ont été retenues sur la plupart des données permutées et agissent positivement sur les essais significativement moins bons que le hasard. Ces variables contribuent donc au rapprochement du hasard.
Au vu des tableaux ci-dessus, on peut effectuer des remarques valables, que les données aient subi ou non des permutations :
- La constante est négative ce qui signifie que l’on se trouve bien sur l’ensemble des essais significativement moins bons que le hasard ;
- Si les participants ont eu la possibilité de choisir la liste des cibles potentielles, le pourcentage de bonnes réponses s’est rapproché de celui attendu sous hypothèse de réponse au hasard ;
- Le fait que les émetteurs ont eu (ou non) une consigne augmente l’échec sur les essais significativement inférieurs au hasard ;
2. Influence de la relation entre les participants
A partir de la question : « Connaissez-vous telle ou telle personne ? (de « pas du tout » à « très bien ») », posée aux participants, nous avons calculé deux ratios :
|
|
|
|
|
|
|
Resgr = |
|
|
Emetsgr = |
|
(score sur les récepteurs = moyenne des notes que les récepteurs ont attribués aux autres membres du groupe des récepteurs)
(score
sur les émetteurs = moyenne des notes que les récepteurs ont attribués aux
membres du groupe des émetteurs)
(score
du groupe = moyenne de toutes les notes attribuées par les récepteurs à tous
les autres participants, émetteurs comme récepteurs)
NB => les émetteurs ne notent personne, les récepteurs notent tout le monde, émetteurs aussi bien que récepteurs.
2.1 Analyse des essais significativement supérieurs au hasard :
On s’intéresse aux essais significatifs à 5% et supérieurs à l’espérance du hasard.
Notons que certaines observations non renseignées par les participants n’ont pas été prises en compte dans la suite de l’étude (cf. tableau ci-dessous).
|
|
Données non permutées |
1ère
permutation |
2ème
permutation |
3ème
permutation |
4ème
permutation |
5ème
permutation |
|
Nombre d’observations
totales |
1079 |
1047 |
1028 |
1052 |
1011 |
1073 |
|
Nombre d’observations
prises en compte pour cette étude |
662 |
624 |
620 |
644 |
616 |
654 |
Voici le tableau récapitulatif des résultats obtenus :
|
|
Données non permutées |
1ère
permutation |
2èrm
permutation |
3ème
permutation |
4ème
permutation |
5ème
permutation |
|
Variable |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
|
Resgr |
- 1.48 |
- 1.49 |
- 1.32 |
- 1.86 |
- 1.34 |
- 1.39 |
|
Emesgr |
+ 0.60 |
+ 0.38 |
+ 0.36 |
+ 0.35 |
+ 0.41 |
+ 0.40 |
|
R² obtenu |
0.11 |
0.11 |
0.07 |
0.13 |
0.09 |
0.09 |
Au vu de ces estimations, on constate que lorsque les notes attribuées aux récepteurs par rapport à celles attribués au groupe sont élevées, cela a pour conséquence de détériorer le succès. Ces constats est valables aussi bien sur les données non modifiées que sur les données permutées.
2.2 Analyse des essais significativement moins bons que le hasard :
On s’intéresse aux essais significatifs à 5% et inférieurs au hasard.
Comme précédemment, nous pouvons souligner que l’étude ne porte que sur un certain nombre réduit d’observations qui s’explique par le fait que ces dernières n’ont pas toutes été renseignées par les participants. (cf. tableau ci-dessous).
|
|
Données non permutées |
1ère
permutation |
2ème
permutation |
3ème
permutation |
4ème
permutation |
5ème
permutation |
|
Nombre d’observations
totales |
410 |
426 |
423 |
435 |
454 |
460 |
|
Nombre d’observations
prises en compte par cette étude |
352 |
363 |
369 |
373 |
383 |
387 |
Voici le tableau récapitulatif des résultats obtenus :
|
|
Données non permutées |
1ère
permutation |
2èrm
permutation |
3ème
permutation |
4ème
permutation |
5ème
permutation |
|
Variable |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
Estimation |
|
Resgr |
+ 1.77 |
+ 2.18 |
+ 1.93 |
+ 1.91 |
+ 2.04 |
+ 1.62 |
|
R² obtenu |
0.12 |
0.13 |
0.15 |
0.13 |
0.13 |
0.11 |
Parmi les essais significatifs et inférieurs au hasard, seule une variable est significative. C’est le ratio « score des récepteurs / score du groupe » qui ressort positivement. Lorsque ce rapport est élevé, le pourcentage de bonnes réponses se rapproche du hasard ce qui est cohérent avec les résultats trouvés sur les essais significativement supérieurs au hasard. Cette remarque concerne aussi bien les données modifiées que les essais non permutés.
3. Conclusion
Cette étude montre que la permutation des cibles ne modifie pas fondamentalement les résultats. En effet, la création de fausses cibles a conduit à une sélection de nouveaux essais significatifs. La régression opérée sur ces derniers a donné des résultats similaires à ceux qu’on avait obtenus sur les données réelles ; ce constat reste valable quant aux variables sociométriques.
On peut donc conclure à une très probable présence de « stacking effect ». Cela suffit à expliquer les résultats de la régression et ne nécessite pas de faire intervenir un « effet psi » pour en rendre compte. Il reste intriguant de constater que la plupart des variables explicatives dégagées faisaient intervenir d’une façon ou d’une autre, les émetteurs… C'est pourquoi nous envisageons de reprendre l'étude en prenant comme variable dépendante la force de la majorité plutôt que le succès ou l'échec de l'essai collectif considéré.
Dès à présent nous avons mené une étude restrictive sur les essais des protocoles à trois et cinq cibles à l'exclusion du protocole à deux cibles car ce dernier pourrait avoir introduit un biais dans le resampling.
 |
 |
 |
 |
 |
 |
 |
© Copyright Bernard AURIOL (email : )
dernière mise à jour le